
区块链行业里有一个很垂直的赛道,技术攻坚很艰涩,这就是对数据进行隐私处理的隐私计算。
为什么呢?
一是因为对数据处理的产品复杂度,二是技术上还有很多很多问题存在。用区块链基础设施来做,太过于简陋,这个举例好像,一个人住进一个没装窗户却有一个窗口的屋子,只能先挂个帘子挡一下。没有装窗户的原因是因为,这个地区没有生产窗框、玻璃的企业,也没有会安装的师傅,只能先用纸糊上或者挂一个帘子,更厉害的,直接把窗户封上。
区块链隐私计算现在就是这种情况。
为了实现web3,未来隐私计算一定会解决数据隐私问题,而这种需求面临的目标是什么?也许是联邦学习。虽然这是一个人工智能领域的基础技术,但它定义了一种数据不离开所有者的数据处理方向。
我们为什么要做数据隐私,也是因为平台等中心化的角色会利用数据做一些分析利用,中心化角色也是利用数据进行深度学习,以汲取数据中的价值。
可见,联邦学习或许是一种目标选择。
先看定义:
联邦学习在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。
再看框架:
两个数据拥有方(企业 A 和 B)的场景是联邦学习的标准统构架。该构架可扩展至包含多个数据拥有方的场景。假设企业 A 和 B 想联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,企业 B 还拥有模型需要预测的标签数据。出于数据隐私保护和安全考虑,A 和 B 无法直接进行数据交换,可使用联邦学习系统建立模型。
第一步:加密样本对齐。系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户,以便联合这些用户的特征进行建模。
第二步:加密模型训练。在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。过程中协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密。A 和 B 分别基于加密的梯度值进行计算,最后把结果汇总给 C。C 将结果解密,分别回传给 A 和 B。
第三步:激励。联邦学习解决了不同机构加入联邦共同建模的问题,建立模型以后模型的效果会在实际应用中表现出来,可以记录在区块链上。提供数据多的机构所获得的模型效果会更好,模型效果取决于数据提供方对自己和他人的贡献。
这个过程里,
数据隔离,不会泄露到外部其他人,满足用户隐私保护和数据安全的需求;训练有效;参与者地位对等,公平合作。
这个时候看,区块链可以在数据所有权、联邦贡献度等部分起到决定性的作用。所以是不是一个非常完美的适合用区块链来做的模型。
但目前的隐私计算区块链还不能完全做到这些,主要问题在于:
1.对数据操作的颗粒度还不能完全去中心化到个人。
2.算力不够、存储不够。
3.只用智能合约无法执行庞大的复杂的过程。
4.缺少PaaS以及BaaS这样的中间层服务。
5.链上应用的隐私需求少。
在这些问题的影响下,确实没办法实现,也许有人会认为,比如链上混币,或者查不到交易详情的隐私币是不是就可以算是另一个方向的隐私了。
对,这是另一个方向的隐私需求,这个需求已经可以实现,只是联邦学习的路会更长远一些。
在联邦学习之前,为了防止交易数据明文、合约代码明文会带来更多的安全问题,具备隐私保护能力的链上环境,可以用黑箱的方式保护交易、保护合约,保护资产。这里面有tee、mpc、zksnark等方式。
这些对于一个复杂的数据训练网络来说,都是简陋的结构了。
以太坊是世界计算机,在以太坊出现之前,互联网先是活在机房里,现在机房构成的庞大算力组合成云,互联网活在云上,云是一个组合的没有硬件限制的世界计算机,只是没有去中心化结构。
在云服务中我们可以看到涉及隐私计算的相关服务已经上线很久,比如AWS的数据湖和数据仓,比如阿里云的datatrust以及腾讯在可信平台上的服务,都是向这个方向看齐。
最后,让我们看看在云服务的架构下形成的可信数据处理架构:
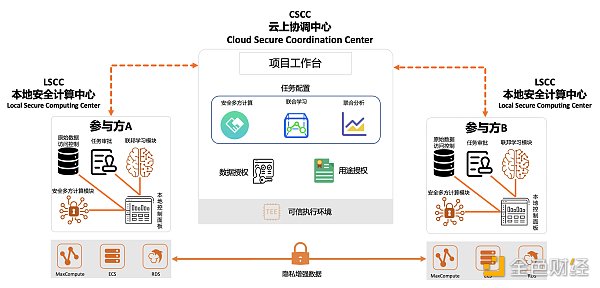
当云服务部分,被联盟链云服务中的区块链所取代或者被去中心化云服务平台取代时,web3就要成功了。











益群网 says:
2aF85ObxjDQWdHBDGQ9tcHr2kVU says:
nimabi says: